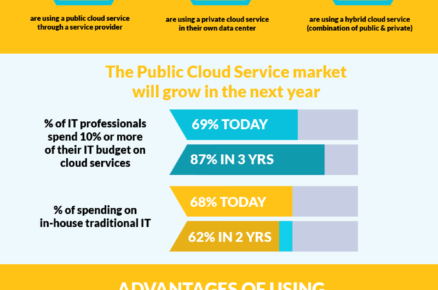
The journey from DNA sequencer to clinical insight is a data gauntlet like few others in science. A single human genome generates 100-300 gigabytes of raw sequence data, which then flows through a complex pipeline of base calling, alignment, variant calling, and finally AI model training—each stage demanding different storage performance characteristics. At the front end, sequencers write data at breakneck speeds, requiring high-bandwidth ingestion that cannot stall. During alignment, random access to reference genomes demands low-latency reads across massive files. At the variant calling stage, millions of small intermediate files create metadata storms that crush traditional filesystems. And at the AI training stage, hundreds of GPUs must simultaneously stream normalized genomic features, checkpoint models, and store results—all while maintaining data integrity and provenance. For research institutions, pharmaceutical companies, and clinical diagnostics labs, storage architecture is not a background detail; it is the primary determinant of how quickly discoveries reach patients. An architecture optimized for one pipeline stage often chokes on another—unless it is purpose-built for the heterogeneity of genomic workloads. This infographic dissects the genomics data pipeline stage by stage, mapping storage requirements to architectural solutions. We examine how Parallel file system for enterprise capabilities handle the metadata intensity of variant calling, how Global namespace unifies data across sequencers, compute clusters, and archival storage, and why Scalable storage architecture is the prerequisite for training foundation models on population-scale genomic datasets. For organizations seeking the Best storage solution for AI workloads in genomics, the choice extends beyond capacity and throughput to include metadata performance, data lifecycle management, and the ability to support both high-performance computing and AI workloads on a single unified fabric. Whether you are evaluating an AI data storage solution, a Big data storage solution, or a dedicated HPC storage solution, understanding how storage architecture shapes the speed from sequencer to AI model is essential to building a research infrastructure that accelerates discovery rather than delaying it. This infographic provides the framework for that understanding—helping genomics leaders align storage strategy with scientific mission.
Get in touch info@tyronesystems.com