

It’s indeed hard for an organization today to exploit the full potential of Big Data. According to one study, “99.95% data is not even analyzed today”. Yet, despite how broadly Big Data is being discussed, it appears that it is still a very big mystery to many. In fact, outside of the experts who have a strong command of this topic, the misunderstandings around Big Data seem to have reached mythical proportions. Here are the top three myths.
Myth 1: Big data is only about substantial Data Volume:
Volume is just one main volume to define Big Data though it is the least important of overall three elements i.e. Variety and Velocity. The 3 V’s of Big Data according to the Gartner’s Doug Laney research report of 2001. This implies that even if you get a real time stream of small data the challenge of managing and getting true insights will be similar to that of Big Data otherwise.
Myth 2: Big Data Is Only At Fancy Term Right Now
According to the Gartner survey in 2014 interest in Big Data technologies and services is at a record high, with 73 percent of the organizations.
The stages of Big Data Adoption, 2013 and 2014 (Review Figure Below)
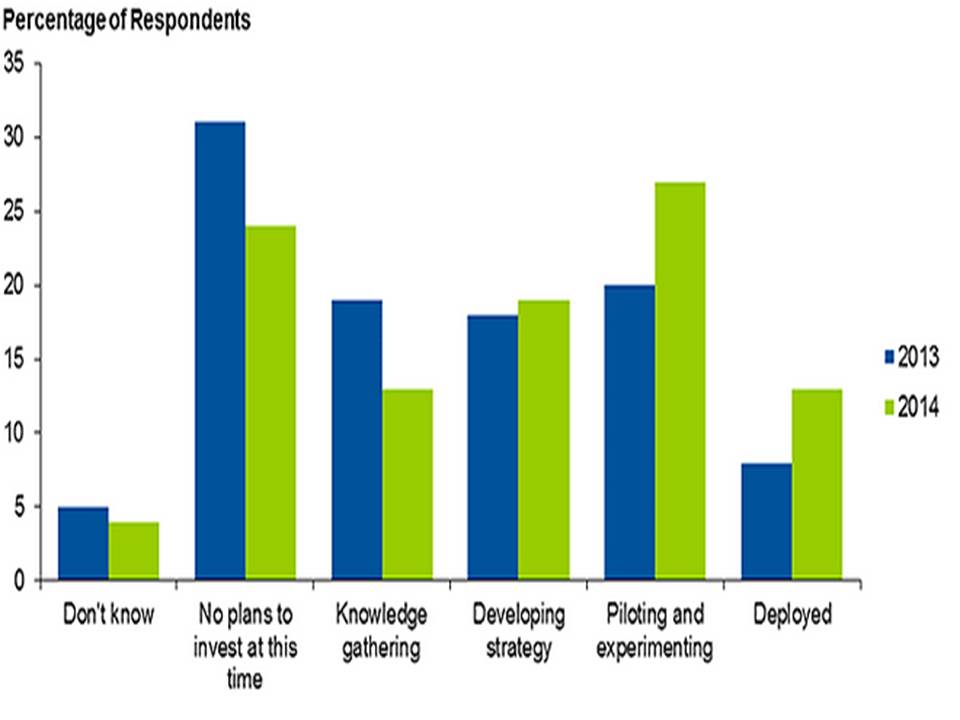
Note: The Gartner asked the survey respondents “Which of the 5 stages best describes your organization’s stage of Big data adoption”
Myth 3: Big Data means Hadoop
Hadoop is an Apache open source software framework for working with Big data Big Data is too varied and complex for a one-size-fits-all solution. While Hadoop has surely captured the greatest name recognition, it is just one of three classes of technologies well suited to storing and managing Big Data. Hadoop is a great fit for staging vast amounts of raw data in order to extract summaries that can then be loaded into traditional enterprise data warehouses to conduct low-latency analytics. Real-time analytics, while making great advances on Hadoop with tools such as Presto and Apache Spark, are still best served by the traditional databases.








