| Executive summary. MLCommons identified Netweb Technologies India Limited as a first-time submitter in MLPerf Inference v6.0, while NVIDIA separately listed Netweb among the 14 partners participating on the NVIDIA platform in the same benchmark cycle. This marks an important moment of global benchmarking recognition for an Indian AI infrastructure company grounded in open, reproducible industry benchmarks. |
Why this milestone matters
In AI infrastructure, credibility is earned with delivered performance, because mere peak chip specifications are not an accurate reflection of real-world performance. That is why Netweb Technologies’ first registered MLPerf Inference benchmark submission is a strategically important milestone: it places the company inside one of the world’s most respected, architecture-neutral AI benchmarking frameworks.
MLCommons states that the MLPerf Inference benchmark suite measures system performance in a representative, reproducible, and architecture-neutral manner, with the published results intended to provide critical technical information for customers procuring and tuning AI systems. In the v6.0 cycle, MLCommons explicitly welcomed Netweb Technologies India Limited as a first-time submitter.
The broader performance context in MLPerf Inference v6.0
The latest MLPerf Inference cycle was extremely important because MLCommons described v6.0 as the most significant revision of the inference benchmark suite to date. The round added or updated major datacenter tests covering reasoning models, a vision-language model, a text-to-video model, and a new generative recommendation benchmark.
NVIDIA’s “extreme co-design” across hardware, software, networking, power delivery, and cooling delivered the highest throughput across the newly added workloads and scenarios, supported by software advances in TensorRT-LLM and Dynamo.
For Netweb, the importance of this context is clear: participation in today’s benchmark ecosystem reflects Netweb’s readiness for full-stack AI infrastructure engineering, where server design, system integration, thermals, networking, software optimization, and deployment orchestration all matter.
Why this is meaningful for Netweb and for Make in India AI infrastructure
This achievement to be treated as the outcome of sustained investment across the Tyrone AI systems roadmap, including NVIDIA-based Grace, GH200, and Grace Blackwell-era platforms, supported by in-house engineering and software assets such as Skylus.ai, KubytsHub, and IntuixAI.
That framing is important because Netweb’s strength is not limited to assembly. The company’s story is rooted in end-to-end design, PCBA, production, rack-scale architecture, deployment capability, and software enablement. In the AI inference era, that breadth of capability is increasingly built for production at scale. This milestone also strengthens the Make in India narrative. It shows that Indian AI infrastructure can participate credibly in a global, reproducible benchmark ecosystem and stand alongside leading international technology brands in an engineering-led performance conversation.
Selected benchmark indicators cited in this blog
The table below summarizes benchmark signals referenced in the narrative.
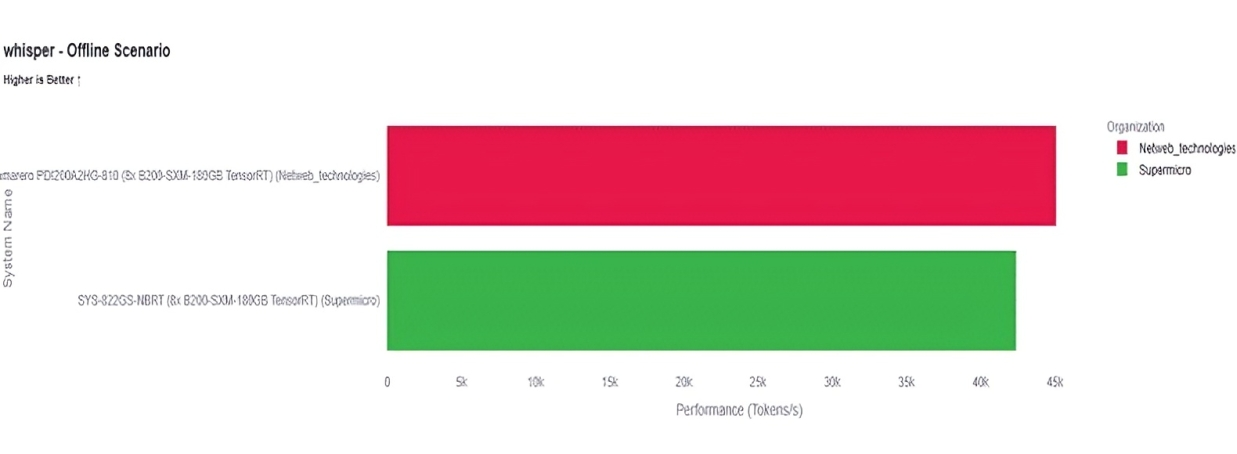
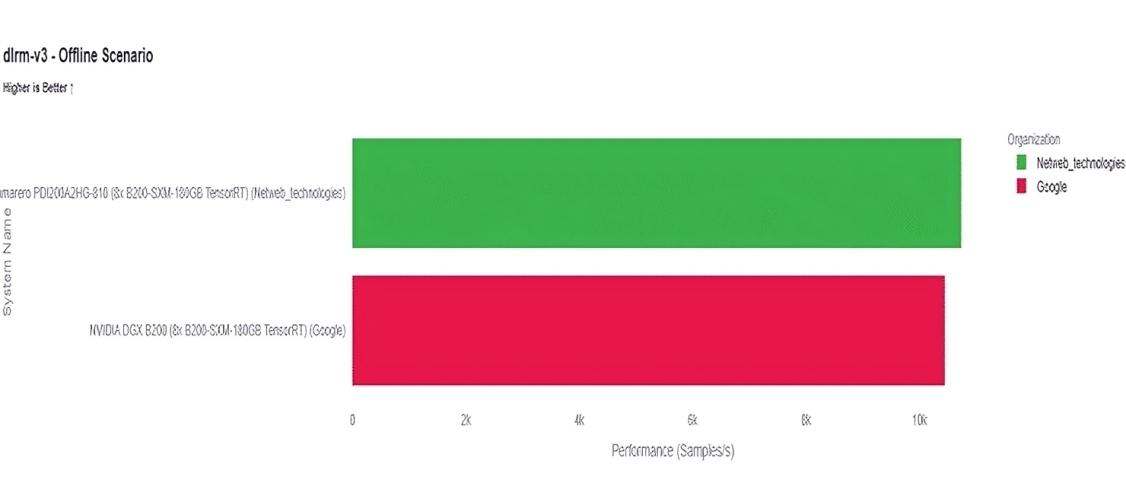
Netweb Technologies submitted the Camarero PDI200A2HG-810, an 8x NVIDIA B200-SXM-180GB TensorRT platform, in the closed datacenter category. Netweb’s official results show strong speech and recommendation inference performance: The comparison charts show Netweb outperforming Supermicro on Whisper Offline, Netweb also exceeds the comparable Google DGX B200 result, highlighting competitive platform tuning for recommendation workloads. Overall, the results establish Netweb’s B200-based system as a credible MLPerf v6.0 inference platform for speech recognition and recommendation use cases.
Official Netweb Results
| Benchmark | Scenario | Result | Quality Metric |
| Whisper | Offline | 45,083.1 samples/s | Accuracy 97.8663 |
| DLRM-v3 | Offline | 10,737.2 samples/s | AUC 0.786289; ACC 0.696426; NE 0.867550 |
| DLRM-v3 | Server | 10,007.0 queries/s | AUC 0.786289; ACC 0.696426; NE 0.867550 |
Sources: MLCommons MLPerf Inference v6.0 release; official MLCommons summary_results.json.
Whisper Offline: Netweb vs Supermicro
DLRM-v3 Offline: Netweb vs Google
Refer: https://mlperf-dashboard-final-50577619532.us-west1.run.app/
Important note. The throughput figures above are drawn from MLCommons v6.0 and NVIDIA’s April 1, 2026 benchmark commentary and are used here only as ecosystem-level performance context. They are not presented as Netweb-specific scores.
Key Takeaway
Netweb Technologies’ first MLPerf Inference submission is more than a benchmark event. It is a signal that Indian AI infrastructure engineering is entering the global performance conversation with greater confidence, deeper systems capability, and stronger manufacturing-backed credibility.
By appearing in the latest MLCommons benchmark cycle and being recognized within NVIDIA’s partner ecosystem, Netweb has established a visible milestone of international benchmarking recognition—one that can serve as a foundation for future benchmark participation, broader market credibility, and stronger positioning in AI infrastructure conversations across enterprise, sovereign, research, and cloud deployments.